ট্রাই ট্রি (Trie tree) ব্যবহার করে আমরা মেমোরি তে কোন স্ট্রিং কে সার্চ করতে পারি। ধরেন আপনাকে একটা সফটওয়্যার তৈরি করতে হবে। যেখানে আপনাকে প্রতিবার একেকটি ওয়ার্ড কে আগে থেকেই মেমোরিতে থাকা ডিকশনারি তে চেক করে দেখতে হবে যে শব্দটির বানান ঠিক আছে কি না। এর একটা সমাধান হতে পারে যে, আমরা আমাদের ডিকশনারি (অ্যারে) কে আগেই সর্ট করে রাখবো। তারপর প্রতিবার শব্দ নিয়ে বাইনারি সার্চ করে দেখবো শব্দ টি আমাদের ডিকশনারি বা অ্যারে তে আছে কি না। থাকলে ওকে না থাকলে নাই। এই সমস্যাটিকে আমরা আবার ডাটা স্ট্রাকচারের ট্রাই ট্রি / প্রিফিক্স ট্রি / রেডিক্স ট্রি দিয়েও সমাধান করতে পারি।
কেনো ট্রাই ট্রি (Trie tree) ব্যবহার করবো?
ট্রাই ট্রি আমরা ব্যবহার কেনো করবো? আমাদের ডিকশনারি থেকে আমরা কিন্তু std::set<string> এবং hash table দিয়েও শব্দ খুজে বের করতে পারি। তবে কেন আমরা ট্রাই ব্যাবহার করবো?
- ট্রাই O(L) সময় এ insert এবং search করতে পারে, set এবং hash tables এর থেকে দ্রুত।
- set এবং hash tables শুধু পুরোপুরি মিলে যায় এমন শব্দ খুজতে পারে। কিন্তু ট্রাই ট্রি দ্বারা আমরা সাধারণ প্রিফিক্স, সিঙ্গেল ক্যারেক্টার মিসিং এমন শব্দ গুলোও খুজে বের করতে পারি।
ট্রাই (Trie) শব্দটি এসেছে ইংরেজি “retrieval” থেকে। কারন ট্রাই শুধু প্রিফিক্স ব্যাবহার করেই ডিকশনারি থেকে শব্দ খুজতে পারে। যদিও এর (trie) উচ্চারন অনেকটা ট্রি এর মতন। তবুও যেহেতু ট্রি শব্দটি বহুল ব্যবহৃত তাই একে ট্রাই ই বলা হয়। ট্রাই ট্রি নিয়ে পড়ার আগে লিঙ্কড লিস্ট নিয়ে ধারনা থাকলে উপকার পাবেন। ট্রাই ট্রি এর বৈশিষ্ট্য গুলো হলোঃ
- ট্রাই ট্রি এর প্রত্যেকটা নোড কোনও না কোনও শব্দের শেষ অথবা প্রিফিক্স।
- রুট নোড একটি খালি স্ট্রিংকে নির্দেশ করে।
ধরেন আপনাকে নিচের মত কিছু শব্দ দেয়া হলো
- Bangali
- Bangla
- Love
- Lover
- Locker
এখন আমাদের টার্গেট হলো এই পাঁচটি শব্দ কে এমন ভাবে মেমোরি তে রাখা যাতে খুব সহজেই খুজে পেতে পারি। প্রথমেই চিত্রের মাধ্যমে কিছু উপস্থাপন দেখা যাক।
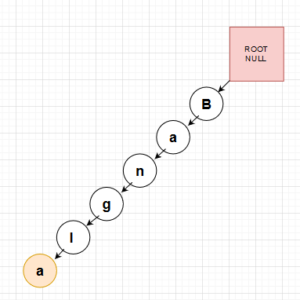
প্রথমে শুধু আমাদের রুট নোড টি থাকবে। এই নোড টি আমাদের রেফারেন্স নোড হিসেবে কাজ করবে। আমরা আমাদের প্রতিটি প্রসেস এই নোড থেকেই শুর করব।

বামে আমাদের রুট নোড টি দেখতে পাচ্ছেন। এই নোড থেকেই আমাদের সকল প্রসেস চালাতে হবে।
এই নোডের সাথে বাকি নোড গুলো আমরা লিঙ্ক করব। এখন আসেন আমরা আমাদের রুট নোড এর সাথে Bangla শব্দটির ক্যারেক্টার গুলোকে লিঙ্ক করি।
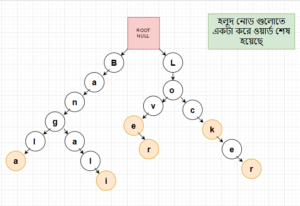
উপরের চিত্রে আমরা Bangla শব্দটির অক্ষর গুলোকে রুট নোড এর সাথে লিঙ্ক করে দিয়েছি। হলুদ নোড টি শব্দটির শেষ নির্দেশ করছে। এবার আমরা Bangali শব্দটি কে লিঙ্ক করব।

এখানে লক্ষণীয় বিষয় হলো, আমরা কিন্তু নতুন শব্দটিকে পুনরায় রুট নোড থেকে আনিনি। পূর্বের Bangla এর g থেকে পরের গুলো শুধু রেখে দিয়েছি। কারণ আমরা দেখতে পাচ্ছি যে Bangla এবং Bangali এর মধ্যে Bang এইটুকু প্রিফিক্স সাধারণ অংশ। একই ভাবে,আমরা আমাদের বাকি অংশটুকু তৈরি করার চেষ্টা করব।

এই অংশে আমরা ৩ টি শব্দ কে রেখেছি। হলুদ নোড গুলো এদের শেষ নির্দেশ করছে। শব্দ গুলো হলো, Love,Lover,Lock,Locker. দেখলেন আমরা কি সুন্দরভাবে ৩ টি শব্দকে রেখে দিলাম।
এখন আসেন আমরা আমাদের ট্রাই ট্রি টি ইমপ্লিমেন্ট করার চেস্টা করি
কোড এ ঝাপ দেয়ার আগে আমি এখানে কিছু কথা পরিষ্কার করে দিবো।
- প্রত্যেকটি নোডে একটি অ্যারে থাকবে child নামে যা ঐ নোড এর পয়েন্টার টাইপ এবং ৫২ সাইজ এর। কারন আমরা ইংরেজী Capital letter এবং Small letter উভয়টা নিয়েই কাজ করবো।
- উক্ত অ্যারেতে আমরা ইনডেক্স করবো নিচের ফাংশন ব্যবহার করে।
- 12345int getId(char ch){int id = ch-'A';if(ch>='a') id-=6;return id;}
আমরা জানি ‘z’-‘A’ = 57 কিন্তু ইংরেজীতে মোট বর্ন আছে ৫২ টি। ৫৭ আসছে কারন ‘a’-‘Z’=7। এখানে ৬ টি বাড়তি আছে। if(ch>='a') id-=6; এখানে আমরা বাড়তি গুলো বাদ দিয়েছি। - Array টির প্রত্যেকটা ইনডেক্স কে NULL তে ইনিশিয়ালাইজ করা হবে।
শুরুতেই আমরা আমাদের নোড এর গঠনটি দেখে নেই।
| 1 2 3 4 | struct node{ bool endmark=0; node* child[52] = {NULL}; // সর্বোচ্চ ৫২ ক্যারাক্টার }; |
এখানে আমরা দুইটা Variable নিয়েছি। একটি হলো bool endmark যা প্রথমে জিরো করা। এইটা ব্যাবহার করে আমরা কোন শব্দ শেষ হয়েছে কি না তা পরিক্ষা করবো। আরেকটি হলো node* child[52] = {NULL}; । এই অ্যারেটিতে আমাদের পরবর্তী চাইল্ড এর অ্যাড্রেস জমা রাখবো। বুঝিয়ে বলছি।
ধরেন আমরা Bangla শব্দটিকে ট্রাই এ insert করবো। তাহলে প্রথমে আমরা b এর জন্য রুট নোড এর child অ্যারের getId('B'); = 1 নং ইনডেক্স এ নতুন একটি নোড এর অ্যাড্রেস দিবো। একই ভাবে আমরা a insert করার সময়, b এর child অ্যারের getId('a') = 26 নং ইনডেক্স এ আরেকটা নোড এর অ্যাড্রেস রাখবো। একই ভাবে বাকি ক্যারেক্টার গুলোও আমরা রেখে দিবো। আশা করি বুঝা গেছে। না বুঝলে সমস্যা নেই। পরের টুকু তে ক্লিয়ার হয়ে যাবে।
শুরুতেই আমরা আমাদের রুট নোডটি তৈরি করে নিবো।
| 1 | node *root = new node; |
ট্রাই ট্রি (trie tree) তে কোনও শব্দ ইনসার্ট করা
ট্রাই ট্রি তে শব্দ ইনসার্ট (insert) করা খুবই সহজ। আগেই বলেছিলাম আমরা রুট নোড নিজে একটি খালি স্ট্রিং কে উপস্থাপন করবে। আমরা আমাদের কোডটিতে একবার চোখ বুলিয়ে আসি
| 1 2 3 4 5 6 7 8 9 10 | void insert(string s){ node *crnt = root;//আমাদের রুট নোড এর এড্রেস কে একটা ভ্যারিয়েবল এর রেখেছি for(int i=0;i<s.length();i++){ int id = getId(s[i]);//কততম ইনডেক্স এ অ্যাড্রেস রাখতে হবে তা হিসাব করেছি if(crnt->child[id] == NULL)//যদি ঐ ইনডেক্স এ আগে থেকেই কোন অ্যাড্রেস না থাকে, crnt->child[id]=new node; //তবে একটি নোড অ্যাড্রেস দিয়ে দেই crnt=crnt->child[id];//ঐ অ্যাড্রেস টি কে বর্তমান অ্যাড্রেস বানাই } crnt->endmark=1;//বর্তমান অ্যাড্রেস এ একটি শব্দ শেষ হয়েছে } |
আমরা উপরের কোডটি দেখি। ২ নং লাইন এ আমরা একটি ভ্যারিয়েবল নিয়েছি crnt নামে। এখানে আমরা বর্তমান নোড হিসেবে রুট নোড কে দিয়ে দিয়েছি। ৩ নং লাইন এ আমরা স্ট্রিং এর ক্যারেক্টার গুলোর উপর লুপ ঘুরিয়েছি।
৪নং লাইন int ascii = s[i]-'A'; এর মাধ্যমে আমরা আমাদের স্ট্রিং এর i তম ক্যারেক্টার s[i] এর জন্য বর্তমান নোড এর child অ্যারের কত তম ইনডেক্স এ তার ভ্যারিয়াবল রাখতে হবে তা বের করেছি এবং মানটি id তে রেখেছি। ৫ নং লাইনে দেখা হয়েছে ঐ ইনডেক্স এ আগেই কোনও নোড অ্যাড্রেস রাখা ছিল কি না। না থাকলে একটি অ্যাড্রেস রেখে দিবো (লাইন ৬) । ৭ নং লাইন এ ঐ অ্যাড্রেস টি কে বর্তমান অ্যাড্রেস করে দিবো crnt এর মাধ্যমে। ৯ নং লাইন টি execute হবে স্ট্রিং টিতে লুপিং শেষ হয়ে গেলে। তখন আমরা বর্তমান নোড এর crnt->endmark=1; করে দিয়ে বুঝাবো এই অ্যাড্রেস এর নোডটিতে একটি শব্দ শেষ হয়েছে।
ট্রাই ট্রি তে শব্দ সার্চ করা
এখন আমরা দেখবো ট্রাই ট্রি (trie tree) তে কিভাবে শব্দ সার্চ করতে হয়। এইটা অনেকটা ইনসার্ট করার মতই। একটু পার্থক্য আছে। চলুন কোড টি দেখি।
| 1 2 3 4 5 6 7 8 9 10 | bool search(string &s){ node *currentNode = root;//আমাদের রুট নোড এর এড্রেস কে একটা ভ্যারিয়েবল এর রেখেছি for(int i=0;i<s.length();i++){//স্ত্রিং এর ক্যারাক্টার গুলোর উপর লুপ int id = getId(s[i]);//কততম ইনডেক্স এ অ্যাড্রেস রাখতে হবে তা হিসাব করেছি if(currentNode->child[id]==NULL) //যদি ঐ ইনডেক্স এ আগে থেকেই কোন অ্যাড্রেস না থাকে, return false;//তার মানে শব্দ টি নেই। তাই আর নিচে গিয়ে কাজ নেই। currentNode = currentNode->child[id];//নতুবা ঐ অ্যাড্রেস টি কে বর্তমান অ্যাড্রেস বানাই } return currentNode->endmark;//বর্তমান অ্যাড্রেস এ একটি শব্দ শেষ হলে true return করবে, নয়তো false } |
প্রথমে আমরা আগের মতই স্ট্রিং এর উপর লুপ চালিয়েছি এবং কততম ইনডেক্স এ i তম ক্যারেক্টার এর জন্য নোড টি আছে তা ৪ নং লাইন এ হিসাব করেছি। ৫ নং লাইন এ দেখেছি যে ইনডেক্স এ নোড টি থাকার কথা সেখানে আসলেই কোনও নোড আছে কি না। না থাকার মানে হলো আমাদের বর্তমান ক্যারেক্টার টি আমরা ফেলে আসা প্রিফিক্স এর নিচে রাখি নি। সুতরাং false রিটার্ন করে দিবো। না হলে ৭ নং লাইন এ আমরা ঐ নোড টি কে ভিজিট করবো।
এবার আসি সবার শেষের লাইন এ। এখানে আমরা currentNode->endmark; রিটার্ন করেছি।কারন আমাদের দুইটি শব্দের সাধারন প্রিফিক্স থাকতেই পারে। তাই আমাদের চেক করে দেখতে হয় এখানে কোন শব্দের শেষ হয়েসে কি না। উদাহরণ হসেবে আমরা love আর lover কে নিতে পারি। love এবং lover এ সাধারণ প্রিফিক্স হলো love। কিন্তু যদি আমরা love কে insert না করে, lover কে করতাম এবং search() এর মাধ্যমে love খুজতাম? তখন কিন্তু স্ট্রিং এর উপর লুপ চলাকালীন false রিটার্ন হতো না। কিন্তু যেহেতু আমরা love রাখিনি তাই অবশ্যই false দেয়ার কথা। এই কাজটিই আমরা return currentNode->endmark; এর মধ্যমে করি। যদি এখানে কনোও শব্দের শেষ হয় তবে অবশ্যই endmark এর মান ১ থাকবে।
এখন আসেন আমরা আমাদের সম্পূর্ণ কোড দেখে নিই
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | /* Sharif Hasan - CSE, PUST Apr 13, 2020 02: 46 AM */ #include<bits/stdc++.h> using namespace std; struct node{ bool endmark=0; node* child[52] = {NULL}; // সর্বোচ্চ ৫২ ক্যারাক্টার }; node *root = new node; int getId(char ch){ int id = ch-'A'; if(ch>='a') id-=6; return id; } void insert(string s){ node *crnt = root;//আমাদের রুট নোড এর এড্রেস কে একটা ভ্যারিয়েবল এর রেখেছি for(int i=0;i<s.length();i++){ int id = getId(s[i]);//কততম ইনডেক্স এ অ্যাড্রেস রাখতে হবে তা হিসাব করেছি if(crnt->child[id] == NULL)//যদি ঐ ইনডেক্স এ আগে থেকেই কোন অ্যাড্রেস না থাকে, crnt->child[id]=new node; //তবে একটি নোড অ্যাড্রেস দিয়ে দেই crnt=crnt->child[id];//ঐ অ্যাড্রেস টি কে বর্তমান অ্যাড্রেস বানাই } crnt->endmark=1;//বর্তমান অ্যাড্রেস এ একটি শব্দ শেষ হয়েছে } bool search(string &s){ node *currentNode = root;//আমাদের রুট নোড এর এড্রেস কে একটা ভ্যারিয়েবল এর রেখেছি for(int i=0;i<s.length();i++){//স্ত্রিং এর ক্যারাক্টার গুলোর উপর লুপ int id = getId(s[i]);//কততম ইনডেক্স এ অ্যাড্রেস রাখতে হবে তা হিসাব করেছি if(currentNode->child[id]==NULL) //যদি ঐ ইনডেক্স এ আগে থেকেই কোন অ্যাড্রেস না থাকে, return false;//তার মানে শব্দ টি নেই। তাই আর নিচে গিয়ে কাজ নেই। currentNode = currentNode->child[id];//নতুবা ঐ অ্যাড্রেস টি কে বর্তমান অ্যাড্রেস বানাই } return currentNode->endmark;//বর্তমান অ্যাড্রেস এ একটি শব্দ শেষ হলে true return করবে, নয়তো false } /*main function*/ int main(){ string s="Love"; insert("Bangali"); insert("Bangla"); insert("Love"); insert("Lover"); insert("Locker"); if(search(s)){ cout<<s<<" found\n"; }else{ cout<<s<<" not found\n"; } return 0; } |
ট্রাই ট্রি এই টাইম কমপ্লেক্সিটি এবং স্পেস কমপ্লেক্সিটি
ট্রাই ট্রি তে insert এবং search করতে O(L) টাইম লাগে। এখানে L হলো স্ট্রিং এর length। কিন্তু ট্রাই ট্রি এর মেমরি কতখানি লাগবে তা ডিপেন্ড করে ইমপ্লিমেন্টেশন এবং শব্দ গুলোর প্রিফিক্স কতখানি ম্যাচ করে তার উপর।
ট্রাই ট্রি এর ব্যাবহার
- ডিকশনারিতে যদি একটি শব্দ খুজতে হয় তখন
- মোবাইল ফোন এর নাম্বার এর সাজেশন দেয়ার জন্য
- ডিকশনারি তে অনেক গুলো শব্দ থাকে। যদি আমাদের দেখতে হয় একটি শব্দ কয়বার প্রিফিক্স হিসেবে এসেছে।
- “Longest common prefix” বের করতে হলে।
কিছু প্রবলেম
আরও পরুন
প্রোগ্রামিং: সেগমেন্ট ট্রি ডাটা স্ট্রাকচার। রেন্জ কুয়েরি: যোগফল
ডাটা স্ট্রাকচার: সেগমেন্ট ট্রি লেজি প্রপাগেশন।
ট্রাই (প্রিফিক্স ট্রি/রেডিক্স ট্রি)
মুটামুটি এই ছিলো আমাদের ট্রাই ট্রি নিয়ে আজকের আলোচনা।কনো সমস্যা কমেন্ট এ জানাতে ভুলবেন না। কোড টি হাতে কলমে খাতায় ড্রয়িং করে করে করলে আরও সহজ লাগবে। হাপি কোডিং 🙂 ।



Banglai comment r problem list dewar jonno attogula thanks vaiya..
ওয়েলকাম 🙂
nice article