এটা মেশিন লার্নিং সিরিজের দ্বিতীয় লেখা। আগের লেখটি এখান থেকে পড়তে পারেন। যদিও আগের লেখায় বলেছিলাম লিনিয়ার রিগ্রেশন নিয়ে লিখবো তারপর ভাবলাম মডেল রিপ্রেজেন্টেশনটাও একটি গুরুত্বপূর্ণ টপিক। তাই এটাকেও কভার করার চেষ্টা করেছি।
লিনিয়ার রিগ্রেশন কি?
লিনিয়ার রিগ্রেশন হলো পরিসংখ্যানের একটি পদ্ধতি, যার মাধ্যমে আমরা কিছু নির্দিস্ট অধীন চলক ( Dependent variable ) এবং কিছু স্বাধীন চলক ( Independent variable ) এর সম্পর্ক মডেল করি। যদি আমাদের স্বাধীন চলক একটি হয় তবে তাকে বলা হয় সিম্পল লিনিয়ার রিগ্রেশন এবং যদি একাধিক স্বাধীন চলক থাকে তবে তাকে বলা হয় মাল্টিপল লিনিয়ার রিগ্রেশন। একইভাবে যখন একের অধিক স্বাধীন চলক এবং একের অধিক অধীন চলক থাকবে তখন তাকে মালটিভারিয়াট লিনিয়ার রিগ্রেশন বলে। এখানে আমাদের স্বাধীন চলক গুলো হলো আমাদের ইনপুট জা আমরা আমদের এলগরিদম কে দিবো। অপরদিকে অধীন চলকগুলো হলো আমাদের এলগরিদম এর আউটপুট। মেশিন লার্নিং এ লিনিয়ার রিগ্রেশন ব্যাবহার করে অবিচ্ছিন্ন কোনও কিছু প্রেডিকশন করি। যেমন, বাড়ির দাম, মার্কেট প্রাইস প্রেডিকশন ইত্যাদি।
মেশিন লার্নিং: লিনিয়ার রিগ্রেশন মডেল উপস্থাপন করা
মেশিন লার্নিং এলগরিদম গুলোর প্রথম কাজ হলো মডেল তৈরি করা। লিনিয়ার রিগ্রেশন এর মডেল মূলত একটি ফাংশন । এই ফাংশনটিকে আমরা বলি হাইপোথিসিস যাকে কিছু ইনপুট দিলে সে সেই মডেল এর উপরে নির্ভর করে কিছু প্রেডিকশন করবে। আমরা আমাদের ইনপুট কে দ্বারা প্রকাশ করবো এবং হাইপোথিসিস আউটপুটকে দ্বারা প্রকাশ করবো। এককথায় বলতে গেলে আমরা ইনপুট এবং অউটপুট এর মধ্যে প্যাটার্ন খুঁজে বের করবো।
বিষয়টা আরেকটু সহজ করতে পারি। ধরা যাক আমার একটা সিস্টেম বানাতে হবে। যেখানে আমি হলাম কোন হাউজিং কম্পানির একজন ইন্জিনিয়ার। আমাকে কম্পানি বিগত ৩/৪ বছরের ডাটা দিয়েছে, যেখানে আমাকে বলা হয়েছে বিভিন্ন বাড়ির বিভিন্ন বৈশিষ্টের ওপর ভিত্তি করে এর দাম কত। এখন আমাকে বলা হলো এমন একটা মেশিন লার্নিং মডেল বানাতে যেখানে ক্লায়েন্ট কোন নির্দিষ্ট বৈশিষ্টের বাড়ির দাম চাইলে আমার মডেল তা প্রেডিকশন করতে পারে। এখানে আমার ডাটাসেটের প্রত্যেকটা বাড়ির যে বৈশিষ্ট তা হলো আমাদের একেকটি ইনপুট , এবং এর বিপরীতে আমরা যা প্রেডিকশন করবো তা হলো আমাদের আউটপুট ।
এখন কথা হলো হাইপোথিসিস ফাংশন টা কেমন? ফাংশনটির একটি উদাহরণ হিসেবে নিচের সমীকরনটি লক্ষ করি,
এখানে
আমাদের হাইপোথিসিস ফাংশন লিনিয়ার বা নন লিনিয়ার দুইটাই হতে পারে। উপরের উদাহরণে ক্যাপিটাল হলো একটি রো ভেক্টর বা একটি Array ( ) যা আমাদের ডেটাসেটের i তম রো এর ডেটাকে উপস্থাপন করে। লক্ষণীয়, এখানে i কিন্তু পাওয়ার বা সূচক না। হলো কিছু ধ্রুবক এবং এগুলো হল আমাদের লার্নিং প্যারামিটার ( একে অনেক জায়গায় Weight বলা হয় )। আমাদের লার্নিং এলগরিদম গুলো মূলত এই কে দরকারমত টিউন করে নেয় ( এমন ভাবে মান প্রদান করে যাতে আমাদের হাইপোথিসিস এর কার্ভটি সবচেয়ে ভালোভাবে ডেটাসেটের মধ্যে ফিট হয়ে যায়) যাতে আমাদের আউটপুট যতটা সম্ভব নিখুঁত হয়। নিচের ছবিটা দেখি

উপরের ছবিতে লাল রেখাটি আমাদের হইপোথিসিস ফাংশন এর কার্ভ। নীল বিন্দুগুলো আমাদের ডাটাগুলোর প্লট। লাল রেখাটি এইমুহুর্তে আমাদের ডাটাগুলোর মধ্যে সবচেয়ে ভালোভাবে ফিট হয়েছে।

উপরে যে ছবিটি দেয়া আছে তা লক্ষ করি। এখানে আমাদের ইনপুট, যা ঘরে ক্ষেত্রফল কত তা প্রকাশ করে। এই মানটাকে আমাদের হাইপোথিসিস ফাংশন এ দেয়া হয়েছে। এখানে আগে থেকে আমাদের ট্রেইনিং সেট কে শিখে নিয়েছে ( দরকার মতো সেট করে নিয়েছে ) নির্দিষ্ট লার্নিং এলগরিদম দ্বারা। ফাংশনটি দরকার মতো ক্যালকুলেশন করে আমাদের কে নির্দিষ্ট আউপুট প্রদান করবে।
আমরা প্রথমে এক চলকের লিনিয়ার রিগ্রেশন দেখবো। পরে একাধিক চলকের দিকে দেখা যাবে।
উদাহরণসরূপঃ সিম্পল লিনিয়ার রিগ্রেশনের ( একটি ইনপুট এবং একটি টার্গেট আউটপুট y ) জন্য আমাদের হাইপোথিসিস ফাংশন হবে,
হলো আমাদের লার্নিং প্যারামিটার , হলো আমাদের টার্গেট আউটপুট এবং হলো আমাদের ইনপুট। বহুমাত্রিক সমস্যার ক্ষেত্রে আমাদের আরও ইনপুট থাকবে। এক্ষেত্রে আমাদের হাইপথেসিস আর একটি সরলরেখা থাকবে না, এটি একটি সমতল (Plane) বা অধি সমতল (Hyper plane) হয়ে যেতো।
উপরে যেই ফাংশনটি লেখা হয়েছে আপনি ইচ্ছা করলে একে একটি দ্বিমাত্রিক () গ্রাফ এ উপস্থাপন করতে পারবেন, যদি আমাদের ইনপুট দুইটি হতো তাহলে ফাংশনটিকে একটি ত্রিমাত্রিক () গ্রাফ এ উপস্থাপন করা যেতো। যদি আমাদের ইনপুট সংখ্যা ৪ হতো তবে কি হতো? চতুর্মাত্রিক গ্রাফে উপস্থাপন করতাম? করলে কি আসলে বুঝতে পারতাম?
এখন পরবর্তি কথা হলো টা আসলে কি? একে বলা হয় বায়াস (Bias) প্যারামিটার। এর ব্যাপারে পরের পর্বে কথা বলবো।
আসেন আমরা আমাদের হাইপথিসিসকে প্লট করার চেষ্টা করি। এজন্য আপাতত ধরে নিই। এখন আমাদের হাইপথিসিস এর প্লট হবে নিচের মতো।

যেহেতু আমাদের সেহেতু আমাদের হাইপথিসিস ফাংশনের কোনও ঢাল নেই এবং আমাদের রেখাটি অক্ষের সমান্তরাল রেখা হয়েছে। আবার ধরা যাক । তাহলে আমাদের হাইপথিসিসের প্লট নিচের মতো হবে,

তো এখন আমাদের উদ্দেশ্য কি?
ধরা যাক এবার আমাদের ডাটাসেট এ কিছু ডাটা (x,y) দেয়া আছে নিচের মত করে।
এখানে প্রতিটা ফিচার এর বিপরীতে আমাদের টার্গেট আউটপুট দেয়া আছে। এই ডাটাগুলোকে যদি এর বিপরীতে কে প্লটকরা হয় তবে নিচের মতো বিন্দুগুলো দেখা যাবে,

আমরা লিনিয়ার রিগ্রেশন ব্যাবহার করে এই ডাটাগুলোর মধ্যে আমাদের হাইপথিসিস কে আঁকার চেষ্টা করবো, যাতে আমাদের প্রেডিকশন সর্বাপেক্ষা নিখুঁত হয়।
গ্র্যাডিয়েন্ট ডিসেন্ট ও কস্ট ফাংশন
উপরে আমরা প্যারামিটার এর কথা বলেছিলাম। কেই আমরা দরকার মত মান প্রদান করব যাতে আমাদের প্রেডিকশন যতটা সম্ভব নিখুঁত হয়।
এখন আমাদের একটা ফাংশন দরকার যা আমাদের এই থেটার নির্দিষ্ট মান এর জন্য আমাদের হাইপোথিসিস এর এরর (Error) পরিমাপ করবে। এই ফাংশনটাকেই আমরা বলি কস্ট ফাংশন।
সাধারণত রিগ্রেশন প্রবলেমগুলোতে কস্ট ফাংশন হিসেবে Mean squared error (MSE) কস্ট ফাংশন জনপ্রিয়। যা আমাদের আউটপুট এবং টার্গেট আউটপুট এর মধ্যে কতোটুকু এরর আছে তা পরিমাপ করে। এই এররকে বিবেচনায় নিয়ে আমরা আমাদের কে optimal পজিশন এ সেট করতে পারি যাতে আমাদের কস্ট বা এরর সর্বনিম্ন হয়।
আমাদের কস্ট ফাংশন,
আমরা যদি আমাদের কস্ট ফাংশনের এর জায়গায় আমাদের হাইপথিসিস বসাই এবং আমাদের হিসেবের সুবিধার জন্য কস্ট ফাংশনকে একটু সহজ করি তবে, আমাদের কস্ট ফাংশন হয়,
এখানে,
- হলো আমাদের ডাটাসেট এ কি পরিমাণ রো বা স্যাম্পল ডাটা আছে তার সংখ্যা।
- আমাদের কস্ট ফাংশন, আমাদের টার্গেট হলো এর নির্দিষ্ট মানের জন্য কে সর্বনিম্ন করা।
- হলো আমাদের i তম স্যাম্পল এর টার্গেট আউটপুট। হলো আমাদের তম স্যাম্পল এর ইনপুট।
- হলো আমাদের হাইপথিসিস যা প্রেডিকশন করেছে তার মান।
কস্ট ফাংশন বুঝার সুবিধার জন্য আমরা কিছু ডাটা নেই। X={1,2,3}, Y={1,2,3}। এখন এই ডাটা পয়েন্ট আঁকারে আমাদের গ্রাফ এ প্লট করি।

এখনকার জন্য আমরা আমাদের প্যারামিটার এর জন্য কিছু মান নিবো ম্যানুয়ালি। আপাতত আমরা কাজ সহজ করার জন্য ধরে নিবো।
ধরি , তাহলে আমাদের হাইপথিসিস ফাংশনটি যা দাঁড়াচ্ছে তা হলো, , সুতরাং হলে আমরা নিচের চিত্রের মতো লাল একটি সরলরেখা পাবো যা আমদের তিনটি বিন্দুকে চমৎকার ভাবে ছেদ করে গেছে। এখানে আমাদের কস্ট ফাংশনের মান 0। , হলে আমরা হলুদ রেখাটির মতো একটি রেখা পাবো।

এখন,আমাদের হলুদ রেখাটির জন্য আমাদের এররের মান শুন্য হবে না। কারণ, আমরা পেয়েছি,
এবং এর জন্য,
এখন কে আমাদের গ্রাফ এ প্লট করি, (ক্রস দিয়ে চিহ্নিত করা)।

একই ভাবে এর জন্য আমাদের কস্ট হবে,
এখন কেউ আমাদের গ্রাফ এ প্লট করে নেই।

এখন আমরা আমাদের বিন্দুগুলিকে সুন্দর করে যুক্ত করে দিবো।

উপরের গ্রাফ থেকে আমরা দেখতে পাচ্ছি, আমাদের হলেই আমাদের কস্ট ফাংশনের মান সর্বনিম্ন হয়। সুতরাং হলো আমাদের প্যারামিটার এর জন্য অপটিমাম সমাধান।
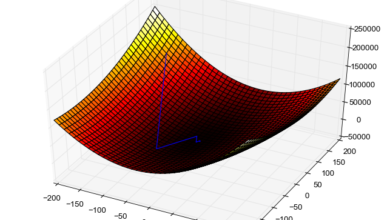
নীল বক্ররেখাটা ঐটা আমাদের কস্ট ফাংশনের গ্রাফ। এখন কথা হচ্ছে যখন আমাদের আরও বড় সমস্যা দেয়া থাকবে তখন তো আমরা আর হাতে হাতে এই সমস্যা সমাধান করবো না। তখন কি উপায়? উত্তর হচ্ছে উপায় আছে, এবং তা হচ্ছে গ্র্যাডিয়েন্ট ডিসেন্ট এলগরিদম।
মেশিন লার্নিং: গ্র্যাডিয়েন্ট ডিসেন্ট
উপরে আমরা আমাদের প্যারামিটার এর জন্য বিভিন্ন মান ধরে নিয়ে আমাদের কস্ট ফাংশনকে মিনিমাইজ করেছি। তো আমরা তো আর আমাদের হাতে করে প্যারামিটারের মান বের করবো না। এর জন্য অবশ্যই ভালো উপায় থাকা উচিত। উত্তর হলো হ্যাঁ আছে, গ্র্যাডিয়েন্ট ডিসেন্ট এলগরিদম, মেশিন লার্নিং এর একটি গুরুত্বপূর্ণ লার্নিং এলগরিদম।
গ্র্যাডিয়েন্ট ডিসেন্ট তাই করে যা আমরা উপড়ে হাতে করে করলাম। একটু একটু করে আমাদের কস্ট ফাংশনের মান মিনিমাম এর দিকে নিয়ে যায় প্যারামিটারের মান একটু একটু করে পরিবর্তন করার মাধ্যমে। আমরা আমাদের প্যারামিটারের মান প্রথমে যেকোনো কিছু নিয়ে নিবো। তারপর আমরা আমাদের প্যারামিটার কে গ্র্যাডিয়েন্ট ডিসেন্ট এর মাধ্যমে আপডেট করবো যাতে আমাদের কস্ট ফাংশনের মান আস্তে আস্তে কমে যায়। আমাদের পারামিটের আপডেট করার মুল সূত্রটি এমন,
এখানে আমাদের হলো লার্নিং রেট। এই প্যারামিটার নির্দেশ করে কতদ্রুত আমাদের এলগরিদম মিনিমাম এর দিকে ধাবিত হবে। অন্তরীকরণ অংশটা হলো এর সাপাক্ষে আমাদের আংশিক অন্তরীকরণ। যেখানে আমাদের কস্ট ফাংশন হলো এবং
নিচের ছবিটা দেখি,

এখানের ab রেখাটি আমাদের কস্ট ফাংশন এর একটি স্পর্শক। কস্ট ফাংশন এবং ab রেখা যেই বিন্দুতে স্পর্শ করেছে এর সাপেক্ষে সেই রেখার ঢাল,
এবং আমাদের কস্ট ফাংশনের মিনিমাম হলো । সুতরাং আমাদের প্যারামিটার এর মান কমাতে হবে। চলুন দেখি কিভাবে গ্র্যাডিয়েন্ট ডিসেন্ট আমাদের প্যারামিটারের মান কমাতে পারে।
আমরা জানি,
সমীকরণ ১ থেকে পাই,
সুতরাং আমাদের প্যারামিটার এখানে ধরে।
অতএব দেখা গেলো গ্র্যাডিয়েন্ট ডিসেন্ট কিভাবে আমাদের প্যারামিটারের মান একটু কমিয়ে দিলো। যদি আরও প্যারামিটার থাকে তবে আমরা একই পদ্ধতি অনুসরণ করে আমাদের কস্ট ফাংশনের মান মিনিমাম করতে পারবো।

আজকে আর লেখছি না। আগামী লেখায় আমরা কস্ট ফাংশন এবং গ্র্যাডিয়েন্ট ডিসেন্ট নিয়ে আরও আলোচনা করবো তখন আমাদের অন্তরীকরণ অংশটুকু সমাধান করা হবে।
আপাতত বিদায়। আর মেশিন লার্নিং,মডেল রিপ্রেজেন্টেশন, কস্ট ফাংশন নিয়ে যার যা কিছু কনফিউশন, কমেন্ট করতে ভুলবেন না।



Please bro, continue
Demanding next part and also implementation..